Topic covered:
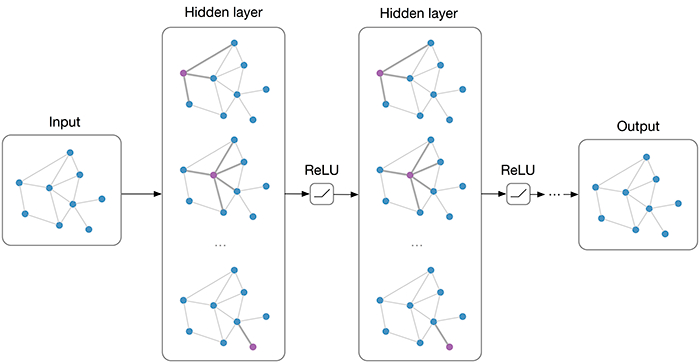
Multi-layer Graph Convolutional Network (GCN) with first-order filters.
Image taken from blog "Graph convolution network by Kipf"
Note
This post includes only basic graph convolution algorithms. It donot include applications of graphs and other algorithms.
Introduction
The great success of Neural Networks for pattern recognition and data mininghas made the researchers to use it in areas like feature engineering, classification etc. Deep architectures like CNN and RNN has revolutionized their use in every domainin which they can be used like text, images, video, signal etc. CNN brought great success on image analysis. The grid structure of image make CNN to exploit local connectivity, translational invariance and shifting to produce meaningful embeddings(low dimensional features) of that image. The growth in computational power and availability of big data are also behind success story of deeplearning architectures.
Researchers thought of using convolution(CNN) on non-grid, irregular structures like graphs. As most ML algorithms needs euclidean distance as similarity notion. Same notion can't be utilised in graphs as it has relative positions. Motivated by CNN, an image can also be thought as special case of graphs where pixel are connected to adjacent pixels.
In graph convolution, one may think as weighted average of node's neighbourhood information. In this post, we will go through graph convolution which has origin in spectral domains.
Spectral Domains
Spectral based methods have solid backing of mathematical foundation in graph signal processing. It assumes that graph is undirected. It uses graph signals and eigen vectors of graph Laplacian matrix. The Global structure can be exploit with spectrum of graph Laplacian to generalize convolution operator.
Mathematically Laplacian has these 3 different forms:
- The unnormalized graph Laplacian matrix is defined as
- The normalized graph Laplacian symmetric matrix is defined as
- The normalized graph Laplacian matrix based on random walk is defined as
D is Degree matrix, also diagonal matrix defined
Some properties of L, Lsym and Lrw are :
- for every vector we have
- L is symmetric and positive semi definite.
- Smallest eigen value of L is 0 and corresponding eigen vector is 1 vector.
- Multiplicity k of eigen value 0 of L, Lsym, Lrw is equal to number of connected component in the graph.
Ideal behind using spectral domains is Convolution is easy in signal domain. One application where it is used predominantly is spectral clustering. We will look into it in detail in some other post. One can go through this paper by Luxburg for more details.
Convolutional Graph Neural Networks
As in above paragraph we have different mathematical definitions for graph
Laplacian matrix. For simplicity take
this is symmetrical Laplacian matrix, also a positive semidefinite matrix.
By diagonalization
is matrix of eigen vectors and
is a diagonal matrix of corresponding eigen values.
In graph signal processing, a signal is node feature defined as .
The Graph fourier transform to a signal X is :
Inverse graph fourier transform is where
is resulted signal from graph fourier transform.
Here GFT project x into a orthogonal basis formed by eigen vectors of normalized Laplacian.
contain element in new feature domains.
So graph convolution is defined as:
where is convolution filter.
All graph spectral convolution follow this same mathematical expression with some approximations.
Spectral CNN
In paper Spectral Network and Deep locally connected network on Graph by Bruna, it is specifically written to
use first d eigen vectors of Laplacian matrix which carry smooth geometry of graph. The cutoff frequency d depends on intrinsic
regularity and sample size. Here spectral CNN assumes
is set of learnable parameters and consider graph signal with multiple channels.
Hence the Graph Convolution layer of Spectral CNN is defined as :
k is the layer index,
is the input graph signal,
is number of input channels,
is
the number of output channels.
It has one big problem, eigen value decomposition is too expensive so it must be replaced by some approximations.
ChebNets or Chebyshev Spectral CNN
Now comes an evolution called ChebNets. It approximate the graph filter
by Chebyshev polynomial.
where
value of
lie in [-1,1].
The Chebyshev Polynomial is defined by :
As a result new convolution of signal x is defined over filter is :
It depends only on nodes that are K-step away from central node (Kth-order neighbourhood).
Here getting eigen vector matrix U is still expensive, one solution is to use parametrize which recursively use L in place of
.
As we know
Hence .
Now the Graph Convolution becomes where
.
The Spectrum of Chebnet is mapped to [-1, 1] linearly. It is great improvement over spectral CNN. Also Kth of Laplacian is exactly K-Localized. Above derivation of expression is too much concentrating as i thought it would be better to show how we remove U which is necessary as it is too expensive to compute.
CayleyNets
CayleyNets is another convolution framework over graph. CayleyNets futher applies Cayley polynomials in place of Chebyshev Polynomial.
Cayley polynomials are parametric rationan complex to capture narrow frequency bands.
The spectral convolution of CayleyNets is defined as:
is real part of complex numbers.
is real coefficient.
is complex coeffiecient.
control the spectrum of Cayley filter.
Graph Convolutional Network
Now we come to most simpler part of convolution on graph which is easy to understand and apply. Although CayleyNets works well nut its too complex equation to understand.
It introduces first order approximation of ChebNets.
As we know in last post that Chebnets equation is given by :
Setting K = 1, we have
From Chebyshev polynomial defined in ChebNets section we know that
An assumption , has been taken to reduce the parameters from overfitting
So overall equation for Graph Convolution reduced to :
One more thing left is self loop, so when we include self loop new Adjacency matrix is :
Now has eigen values in [0, 2], repeated operation of this can lead to numerical
instabilities along with exploding and vanishing gradient when used in Deep Neural Network models.
To alleviate this problem, Renormalisation trick is used. In Renormalisation trick, we replace with
where
is defined as:
and
is new Adjacency matrix.
Now the main graph convolution expression with all improvement is:
is convolved signal matrix.
can be efficiently implemented as product of sparse matrix with dense matrix.
The whole derivation might be confusing for first time. If going by simple intution we know that a a classifier
(may be shallow neural network or Logistic classifier) can be where f is some non linear function like sigmoid/Relu/Softmax etc,
is learnable parameters(weights) and
is the feature vector.
In GCN we simply replace with
. By doing this we are aggregating all the features of nodes in neighbourhood. Some nodes has small number of neighbours while
some has large neighbourhood, so aggregated features may not scale properly, hence we used normalised Laplacian to make them in same range.
this equation is showing us that we are simply taking aggregate mean of node features along with neighbour's node features. This equation is first order approximation of ChebNet with some improvement. It is the expression for single layer of Graph Convolution Networks. To get Kth order Graph Convolution filter we can stack K layers of GCN. K layer of GCN stacking is simply like K layer MLP.
In the original paper of GCN by Thomas Kipf, ReLu is used as Non-linear activation function. In paper SGC(Simplifying-GCN , it is written that non-linear function contribution to actual performance is very less, main contribution comes from local averaging of node features.
By doing this way they have shown to reduce the complexity too much resulting in too less training time(as linear classifier trained easily in less time ) and above or at par performance than original GCN.
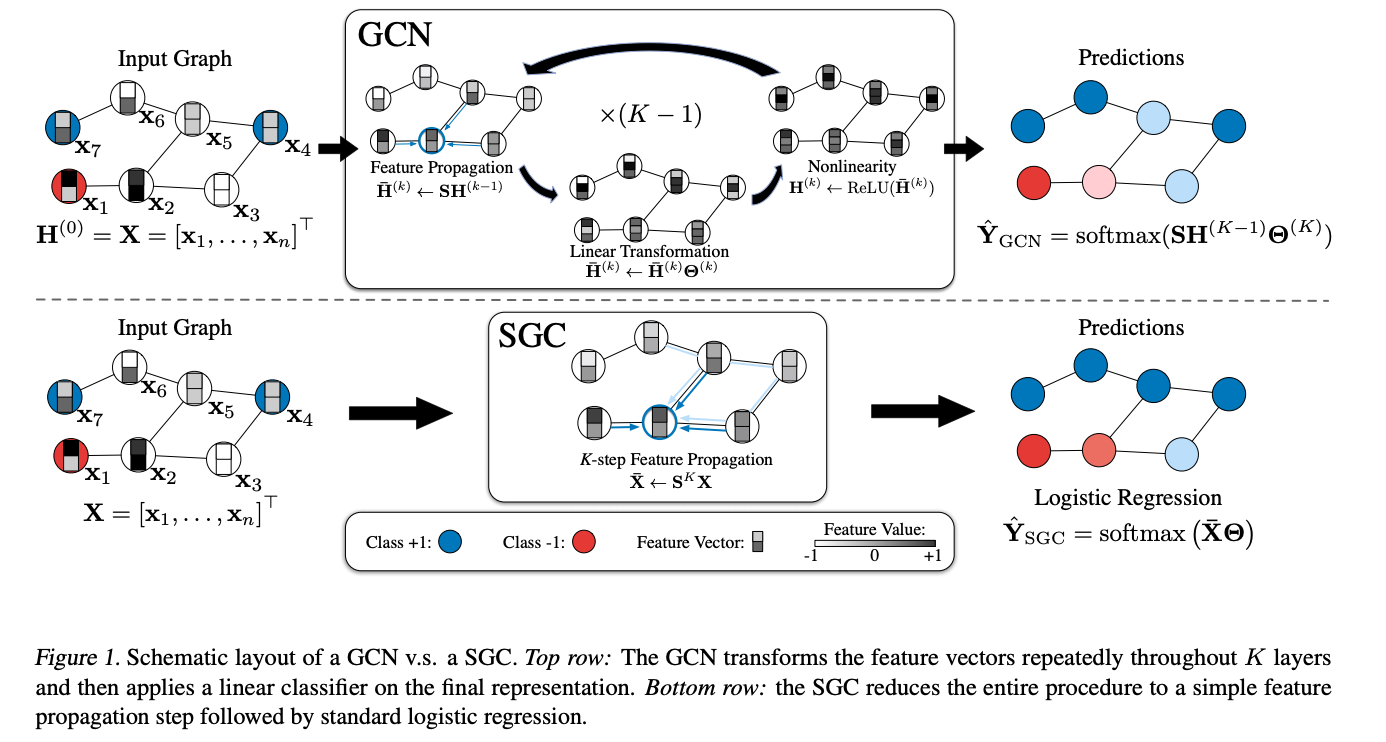
this figure is taken from SGC paper , It tells us about the how SGC and GCN works
There are some other modificatios of GCN like Large-Scale Learnable Graph Convolutional Networks, Attention-based graph convolutional networks, Dynamic Graph Convolutional Network etc. which we will not discuss here.
Some results and analysis
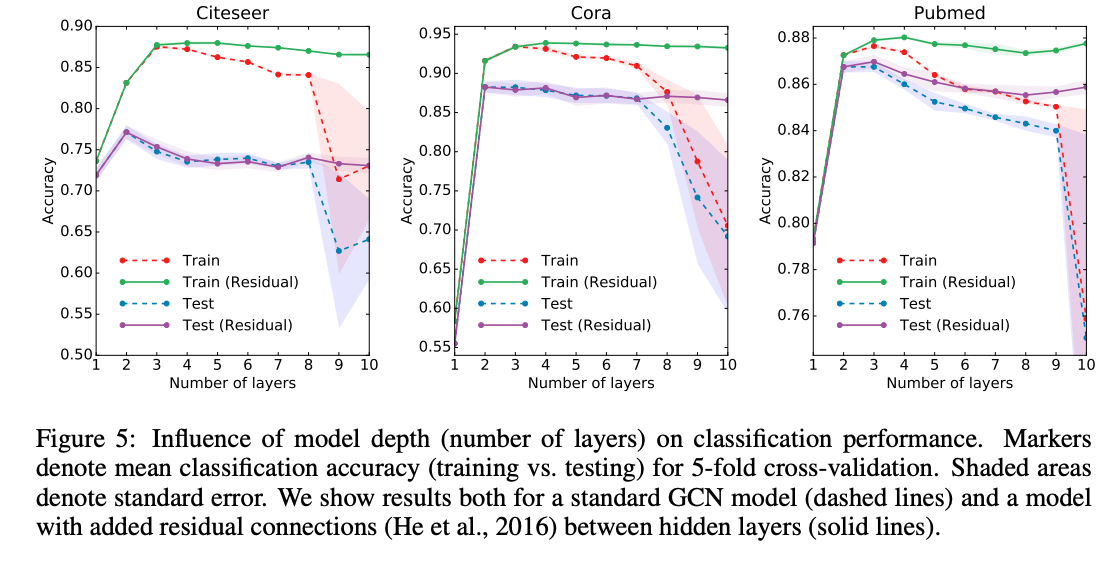
This image is taken from GCN paper(mentioned in reference).
It show how the performance vary with respect to number of layers on 3 data sets Cora, Citeseer, and Pubmed.
We can see from the figure that stacking large numbers of GCN layer make the model overfit on all dataset, this is due to high complexity. The best result is when two layers are stacked togethers. For GCN layer stacked greater than 2, perfomance either remain constant or got overfit. For count of GCN layers less than 2, model got underfit.
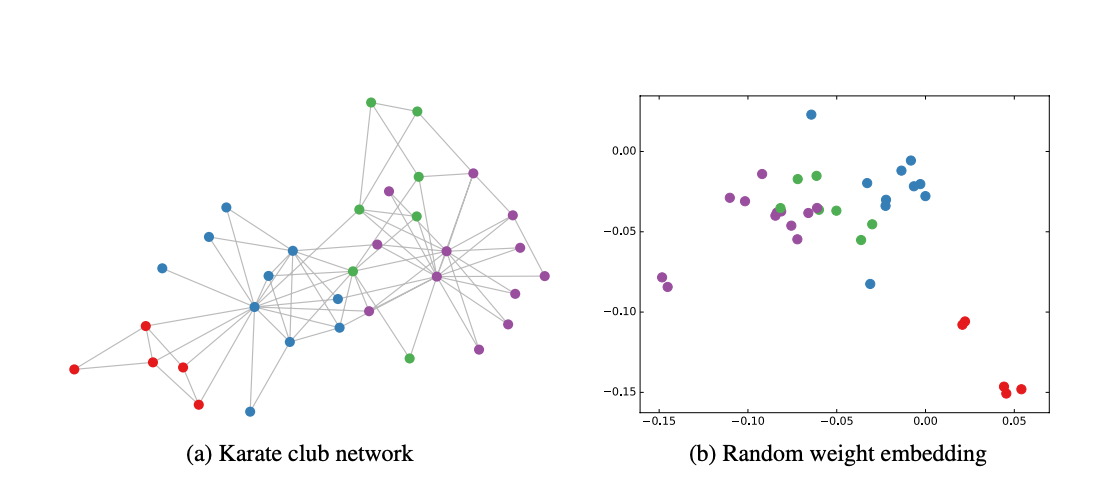
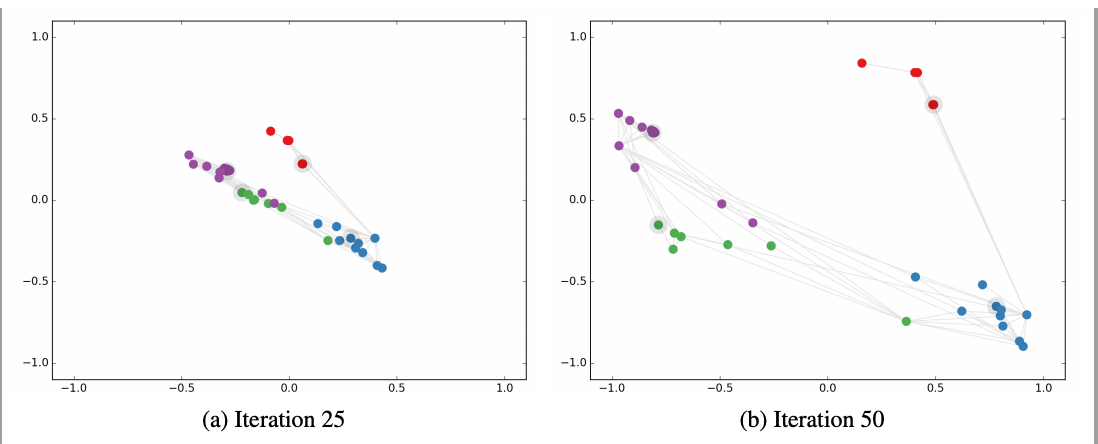
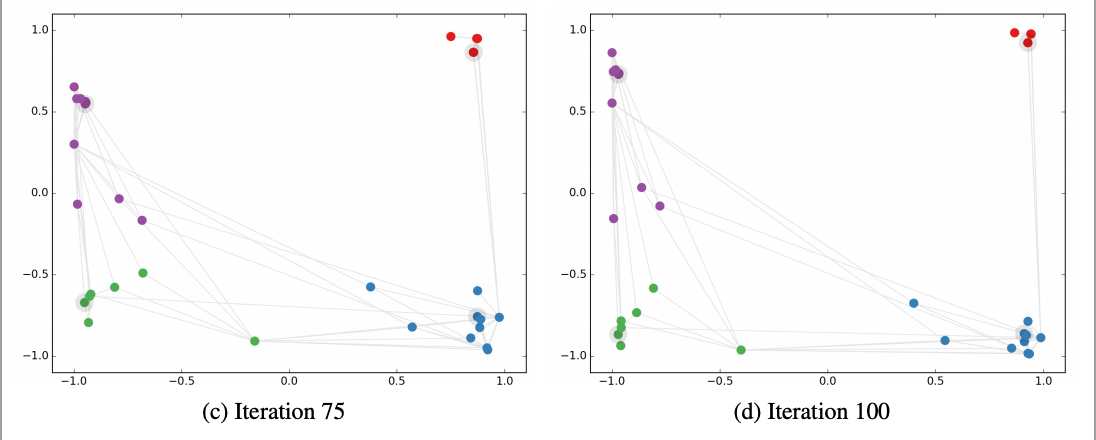
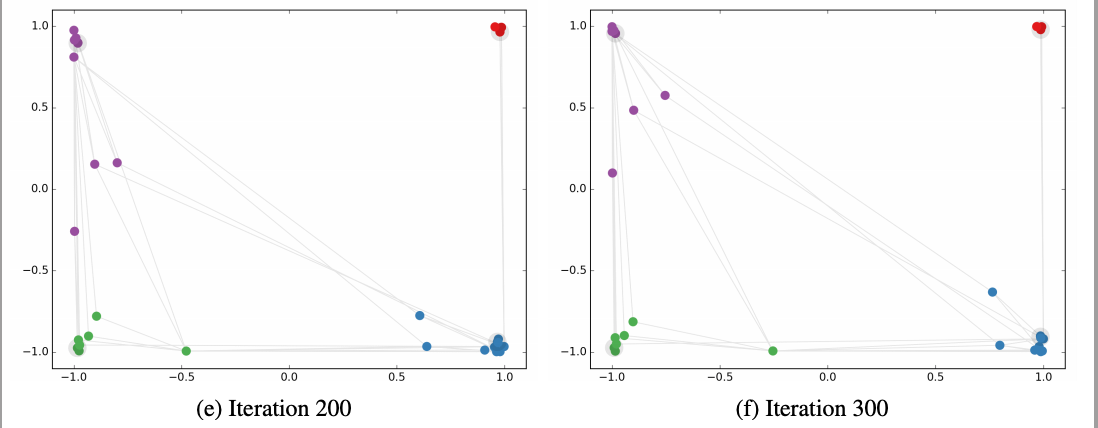
This image taken from GCN paper. It show how embedding on dataset mentioned Karate Club
projections change as GCN get trained with respect to iterations
Above image shows the embedding projections of nodes in Karate club graph. As GCN got trained, the similar nodes are getting more closer. Movement of forming clusters can be notice with respect to iterations.
| Framework | Accuracy on Cora Dataset | Accuracy on Citeseer Dataset | Accuracy on Pubmed Dataset |
|---|---|---|---|
| ChebNets | 81.2% | 69.8% | 74.4% |
| GCN | 81.5% | 70.3% | 79% |
| CayleyNets | 81.9% | - | - |
| SGC | 81% | 71.9 | 78.9% |
The result mention taken from standard papers result portions like GCN, SGC, GAT etc. From result we can see that GCN improvement make the perfomance increased by some points with respect to ChebNets. CayleyNets is better than GCN on Cora. Lastly SGC mentioned above is at par with respect to GCN with too much reduced complexity and faster training.
Special points about GCN
- From results and analysis section, good results is found by stacking 2 layers, more than that cause either no change or overfitting.
- In random graphs, one can have maximum of diameter of 6 which restrict us not to use more layer of GCN as it will make all nodes feature alike.
Problems with spectral domains
- Highly complex and inefficient, although GCN is effiecient.
- Spectral models rely on graph fourier basis which generalises poorly on new graphs. They assume fixed graph, any peturbation would change the eigen basis.
- Spectral models are only used for undirected graphs, so flexibilty remains less as can't be used for other types of graphs.
Conclusions
I tried to be flexible, only covering graph convolution related with spectral domains. Some part of the post are more theoritical which are not understandable in one go, for that i have mark some paper in references. I don't go through other parts like training. All models are trained in similar fashion like simple neural network with backpropagation and cross entropy as loss functions. In some other post, i will go through in details about practical applications of graph.
There are other algorithms in graph machine learning not originated in spectral domains like random walks based method e.g. Deepwalk, Node2vec, SDNE, LINE etc.
Reference
- A Tutorial on Spectral Clustering by Luxburg.
- Spectral Network and Deep locally connected network on Graph by Bruna.
- GCN by Thomas Kipf
- SGC(Simplifying-GCN) by Wu.
- A Comprehensive Survey on Graph Neural Networks by Z. Wu
- Convolutional Neural Networks on Graphs with Fast Localized Spectral Filtering by Michaël Defferrard
From
Swyam Prakash Singh, ML enthusiast